到目前为止,您可能已经对 Erlang 项目的结构有了相当不错的了解。结合任何关于语言基础的指南,您应该能够顺利开始。但是,有一些复杂主题目前在任何现有的 Erlang 文档中都没有得到很好的涵盖。在本章中,我们将指导您如何处理 Unicode、时间和 SSL/TLS 配置等任务。
请注意,这三个主题本身就非常复杂。虽然我们将提供一些关于每个主题的背景信息,但您不会立即成为处理它们的专家——了解其复杂性有助于避免重大错误。
处理 Unicode
Erlang 在字符串处理方面有着相当糟糕的声誉。这在很大程度上是由于它没有专门的字符串类型,并且多年来,除了社区库之外,没有提供良好的 Unicode 支持。虽然前者没有改变,但这种方法确实有一些优势,并且后者最终在最近的 Erlang 版本中得到了解决。
Unicode 背景信息
简而言之,Unicode 是一套关于如何在计算机中处理文本的标准,无论用户使用哪种语言(真正的语言,而不是编程语言)。它已经成为一个包含大量极其复杂考虑因素的庞大规范,涵盖了各种细节,开发人员经常会因此感到迷茫。
即使不了解所有关于 Unicode 的知识,您也可以了解足够的信息来提高效率并避免最明显的错误。首先,我们将介绍一些术语
- 字符:在 Unicode 中,“字符”一词的定义有点模糊。每次看到“字符”这个词时,想象一下与您交谈的人正在使用一个非常抽象的术语,它可以指给定字母表中的任何字母、某些图形(如表情符号)、重音符号或字母修饰符(如
¸和c,组合成ç)、控制序列(如“退格”)等等。这主要是一种常用但不准确的指代文本片段的方式,您不应赋予它太多意义。Unicode 有自己更好、更精确的定义。 - 码位:Unicode 标准在一个大的列表中定义了所有可能的、基本的“字符”(以及其他一些),每个字符都有一个唯一的标识符。该标识符就是码位,通常表示为
U+<十六进制数字>。例如,“M”的码位是U+004D,而♻的码位是U+267B。您可以在Unicode 表中查看完整列表。 - 编码:虽然码位只是表示索引的整数,但这不足以在编程语言中表示文本。历史上,许多系统和编程语言使用字节(
0..255)来表示语言中所有有效的字符。如果您需要更多字符,则必须切换语言。为了与各种系统兼容,Unicode 定义了编码,允许人们根据各种方案表示码位序列。UTF-8是最常见的编码,它使用字节表示所有内容。它的表示结构与ASCII或Latin-1基本相同,因此在拉丁语和日耳曼语中变得非常流行。UTF-16和UTF-32是另外两种替代方案,它们表示更宽的序列(16 位或 32 位)。 - 代码单元:代码单元指定给定码位在给定编码中的编码方式。每个码位在 UTF-8 中占用 1 到 4 个代码单元。例如,
F在 UTF-8 中仅占用46作为代码单元,在 UTF-16 中占用0046,在 UTF-32 中占用00000046。相比之下,©的码位是U+00A9,但在 UTF-8 中表示为两个代码单元(C2和A9),在 UTF-16 和 UTF-32 中表示为一个代码单元(分别为00A9和000000A9)。 - 字形:字符的图形表示。例如,
U+2126是“欧姆符号”,表示为Ω,而U+03A9是“希腊大写字母欧米茄”,也表示为类似的Ω。在某些字体中,它们将相同,在某些字体中则不同。同样,字母“a”可能由看起来像“а”或“α”的字形表示。某些码位没有关联的字形(例如“退格”),而某些字形可用于表示多个码位的连字(例如æ表示ae)。 - 音节簇:到目前为止提到的所有术语都与非常抽象的概念有关。Unicode 具有诸如组合标记和将多个码位组合成一个“字符”的方法等奇特内容。这可能会非常令人困惑,因为用户认为的字符与程序员认为的字符并不相同。音节簇是指“用户认为是单个字符的文本单元”。例如,字母“ï”由两个码位组成:拉丁小写字母
i(U+0069)和一个组合分音符(¨为U+0308)。因此,对于程序员来说,这将显示为两个码位,在 UTF-8 中使用 3 个代码单元进行编码。但是对于用户而言,他们希望按下“退格”键将删除分音符和字母“i”。
这些内容很多,但了解它们很重要。程序员编写字符的方式与最终显示给用户的字符之间没有直接关系。
一个特别有趣的例子是阿拉伯语连字符Bismillah Ar-Rahman Ar-Raheem,它是一个单独的码位(U+FDFD),但在图形上表示为“﷽”。这是 Unicode 标准中目前最宽的“字符”。它代表了一个完整的阿拉伯语句子,被添加到标准中是因为它在多个乌尔都语文档中是法律要求,而它们的键盘布局无法输入阿拉伯语。这是一个用来与 UI 人员开玩笑的绝佳 Unicode 字符。
大多数语言都存在图形(和逻辑)表示与创建最终字符的基础代码不一致的问题。这些问题存在于各种语言中所有可能的连字符和“字符部件”组合中,但对于表情符号,您还可以通过组合个人来创建家庭:👩👩👦👦是一个由 4 个组件和组合标记组成的家庭:👩 + 👩 + 👦 + 👦,其中+是两个女性和两个男性之间的一个特殊组合标记(一个零宽度连接符)(如果您正在旧版浏览器、旧版字体或本书的 PDF 版本上查看此文档,则您可能会看到 4 个人而不是一个家庭)。如果您逐字节或逐码位读取该序列,则会将家庭拆散并更改文本的语义含义。
如果您在传统上对语言环境和各种特定语言规则具有良好支持的文本编辑器(例如 Microsoft Word(我们知道的为数不多的能够在语言需要时自动处理半角空格和不间断空格的编辑器之一))中编辑文本,则按下👩👩👦👦上的退格键会将整个家庭作为一个单元删除。如果您在 FireFox 或 Chrome 中执行此操作,则删除一个“字符”需要 7 次退格:每个“人”一次,每个零宽度连接符一次。Slack 会将它们视为单个字符,而 Visual Studio Code 的行为类似于浏览器(即使两者都是 Electron 应用),而 Notepad.exe 或许多终端模拟器则会将它们扩展为 4 个人,并隐式删除零宽度连接符。
这意味着,无论您使用哪种编程语言,如果字符串看起来像数组,您可以在其中按位置或通过某个索引获取“字符”,那么您很可能会遇到严重的问题。
更糟糕的是,某些“字符”在 Unicode 中有多种可接受的编码。字符é可以通过编码单个码位(U+00E9)或作为字母e(U+0065)后跟´(U+0301)来创建。在法语中,这在逻辑上将是相同的字母é,但使用两种不同形式的两个字符串将不相等。因此,Unicode 引入了诸如规范化之类的概念,它指定了如何根据四种可能的标准(NFC、NFD、NFKC 和 NFKD)强制转换字符串的表示形式(如果您不知道使用哪一个,请坚持使用 NFC)。
字符串排序还引入了诸如排序规则之类的概念,这需要在排序时了解当前使用的语言。
简而言之,为了在您的程序中很好地支持 Unicode,无论您使用哪种编程语言,都必须将字符串视为一种不透明的数据类型,您只能通过支持 Unicode 的库对其进行操作。否则,您就是在操作字节序列或码位序列,并且可能会在人类可读级别意外地破坏某些内容。
在 Erlang 中处理字符串
Erlang 对字符串的支持最初看起来有点奇怪:它没有专门的字符串类型。但是,考虑到 Unicode 的所有复杂性,它实际上并没有那么糟糕。由于所有可能的替代表示形式,使用一个字符串类型通常与使用没有字符串类型一样棘手。
使用反映多种编码的可变字符串类型的编程语言的用户现在可能会感到沾沾自喜,但您会发现,考虑到所有情况,Erlang 具有相当不错的 Unicode 支持——只有排序规则似乎缺失。
数据类型
在 Erlang 中,您必须注意字符串的以下可能的编码
"abcdef":一个字符串,它直接由列表中的 Unicode 码位组成。这意味着,如果您在 Erlang shell 中编写[16#1f914],您将直接获得"🤔"作为字符串,而不考虑编码。这是一个单向链接列表。<<"abcdef">>作为二进制字符串,它是<<$a, $b, $c, $d, $e, $f>>的简写。这是一个旧标准的 Latin1 整数列表,转换为二进制格式。默认情况下,此文字格式不支持 Unicode 编码,如果您在其中放入过大的值(例如16#1f914),例如在源文件中声明一个像<<"🤔">>这样的二进制文件,您将发现自己遇到了溢出,最终的二进制文件为<<20>>。这是使用 Erlang 二进制文件(本质上是不变的字节数组)实现的,旨在处理任何类型的二进制数据内容,即使它不是文本。<<"abcdef"/utf8>>表示一个以 UTF-8 编码的二进制 Unicode 字符串。这种方式可以支持表情符号。它仍然以 Erlang 二进制数据的方式实现,但/utf8构造器确保了正确的 Unicode 编码。<<"🤔"/utf8>>返回<<240,159,164,148>>,这是在 UTF-8 中表示思考表情的正确序列。<<"abcdef"/utf16>>表示一个以 UTF-16 编码的二进制 Unicode 字符串。<<"🤔"/utf16>>返回<<216,62,221,20>><<"abcdef"/utf32>>表示一个以 UTF-32 编码的二进制 Unicode 字符串。<<"🤔"/utf32>>返回<<0,1,249,20>>["abcdef", <<"abcdef"/utf8>>]:这是一个特殊的列表,称为“IoData”,可以支持多种字符串格式。你的列表可以像往常一样包含代码点,但为了避免编码混合导致的问题,你需要确保所有的二进制数据都使用相同的编码(理想情况下是 UTF-8)。
如果你想处理 Unicode 内容,你需要使用 Erlang 中各种与字符串相关的模块。
第一个是 string,它包含诸如 equal/2-4 之类的函数,用于处理字符串比较(包括大小写敏感性和规范化)、find/2-3 用于查找子字符串、length/1 用于获取音位簇的数量、lexemes/2 用于根据某个模式分割字符串、next_codepoint/1 和 next_grapheme/1 用于逐个读取字符串的位、replace/3-4 用于替换、to_graphemes/1 用于将字符串转换为音位簇列表,以及 lowercase/1、uppercase/1 和 titlecase/1 等函数用于处理大小写。该模块还包含更多内容,但以上内容应该具有代表性。
你还可以使用 unicode 模块来处理各种字符串格式、编码和规范化形式之间的转换。正则表达式模块 re 可以很好地处理 Unicode(只需将 unicode 原子传递给它的选项列表),如果你传入 ucp 选项,还可以使用 通用字符类型。最后,file 和 io 模块都支持特定的选项来确保 Unicode 正确工作。
所有这些模块都适用于任何形式的字符串:二进制数据、整数列表或混合表示。只要你坚持使用这些模块来处理字符串,你就会处于良好的状态。
你需要记住的一件棘手的事情是字符串的编码是隐式的。当字符串进入你的系统时,你必须知道它的编码是什么:HTTP 请求通常会在标头中指定编码,XML 也是如此。例如,JSON 和 YAML 要求使用 UTF-8。在处理 SQL 数据库时,每个表都可能指定自己的编码,但数据库本身的连接也会指定编码!如果任何一个不一致,你就会破坏数据。
因此,你需要尽早了解和识别你的编码,并对其进行良好的跟踪。这不仅仅是你的语言中存在哪种数据类型的问题,而是你如何设计你的整个系统以及如何处理网络数据交换的问题。
关于字符串,我们还可以讨论另一件事:如何有效地转换它们。
IoData
那么你应该使用哪种字符串类型呢?有很多选择,但选择一个并不容易。
快速指南如下:
- 对于 UTF-8 使用二进制数据,这应该代表你大部分的使用场景
- 如果你需要使用 UTF-16 和 UTF-32,也应该使用二进制数据
- 列表作为字符串在实践中很少使用,但如果你想在代码点级别工作,它可以非常有效
- 对于其他所有情况,特别是构建字符串时,请使用 IoData。
二进制数据类型的一个优点是它们能够高效地创建子切片。例如,我可能有一个包含 <<"hello there, Erlang!">> 之类内容的二进制数据块,如果我使用 <<Txt:11/binary, _/binary>> 这样的模式匹配一个子切片,那么 Txt 现在就引用了 <<"hello there">>,它与原始数据位于同一内存位置,但无法以编程方式获取父上下文。它是对原始内容子集的有界引用。列表则不然,因为它们是递归定义的。
最重要的是,大于 64 字节的二进制数据可以在进程堆之间共享,因此你可以廉价地在虚拟机中移动字符串内容,而无需像其他数据结构那样付出相同的复制成本。
警告
二进制数据共享通常是提高程序性能的好方法。但是,存在一些病态的使用模式,其中二进制数据共享会导致内存泄漏。如果你想了解更多信息,请查看 Erlang In Anger 中关于内存泄漏的章节,特别是第 7.2 节。
不过,真正酷的事情来自 IoData 表示,你可以在其中将列表方法与二进制数据结合起来。这是你获得真正廉价的不可变字符串组合的方式。
Greetings = <<"Good Morning">>,
Name = "James",
[Greetings, ", ", Name, $!]
此处的最终数据结构类似于 [<<"Good Morning">>, ", ", "James", 33],它是一个混合列表,包含二进制子部分、文字代码点、字符串或其他 IoData 结构。但是,VM 机制都支持将其视为一个扁平的二进制字符串进行处理:IO 系统(网络和磁盘访问)以及上一节中提到的模块都无缝地将此字符串处理为 Good Morning, James!,并提供完整的 Unicode 支持。
因此,虽然你无法修改字符串,但无论它们最初是什么类型,你都可以在恒定时间内追加和匹配大量字符串。如果你正在编写处理字符串的库,这将产生有趣的影响。例如,如果我想将所有 & 实例替换为 &,并且我从 <<"https://example.org/?abc=def&ghi=jkl"/utf8>> 开始,我可能只会返回以下链接列表
% a list
[%% a slice of the original unmutated URL
<<"https://example.org/?abc=def"/utf8>>,
%% a literal list with the replacement content
"&amp",
%% the remaining sub-slice
<<"ghi=jkl"/utf8>>
]
然后你得到一个字符串,它实际上是 3 个元素的链接列表:原始字符串的切片、替换的子集、原始字符串的其余部分。如果你正在替换一个占用 150MB RAM 的文档,并且替换相对较少,那么你可以构建整个文档并在本质上没有开销的情况下对其进行编辑。这非常棒。
那么,IoData 字符串为什么还算酷呢?好吧,Unicode 表示法是一件有趣的事情。如前所述,当你希望像人类一样操作 Unicode 字符串(而不是程序员唯一关心的二进制序列)时,音位簇是 Unicode 字符串的一个关键方面。而大多数使用字节的扁平数组来表示字符串的编程语言都没有很好的方法来迭代字符串,Erlang 的 string 模块允许你调用 string:to_graphemes(String) 来处理它们。
erl +pc latin1 # disable unicode interpretation
1> [Grapheme | Rest] = string:next_grapheme(<<"ß↑õ"/utf8>>),
[223 | <<226,134,145,111,204,131>>]
2> string:to_graphemes("ß↑õ"),
[223,8593,[111,771]]
3> string:to_graphemes(<<"ß↑õ"/utf8>>),
[223,8593,[111,771]]
这使你能够获取任何 Unicode 字符串,并将其转换为一个列表,可以使用 lists:map/2、列表推导式或模式匹配安全地进行迭代。这只能通过 IoData 完成,并且这甚至可能比仅使用默认的 UTF-8 二进制字符串获得的格式更好。
请注意,模式匹配在那里仍然存在风险。理想情况下,你首先需要进行一轮规范化,以便可以以多种方式编码的字符强制转换为统一的表示形式。
希望这能让你对 Erlang 的字符串有一个更清晰的认识。
处理时间
时间本身很容易体验,但描述起来却异常困难。哲学家和科学家们几个世纪以来一直在争论,才最终达成了一致意见,而我们软件从业者认为,从 1970 年 1 月 1 日开始计数秒就足够好了。但这比这更复杂。我们不会深入探讨日历规则和转换、时区、闰秒概念等所有细节;这太泛泛了。但是,我们将介绍 挂钟时间 和 单调时间 之间的一些重要区别,以及 Erlang 虚拟机如何帮助我们处理这些问题。
时间背景信息
如果我们想非常简化,时间测量的具体用例有几个,而且它们通常相当不同。
- 了解两个给定事件之间的时间间隔,或者“某件事需要多长时间?”,这需要使用微秒、小时或年等单位得到一个单一的值。
- 在时间线上放置一个事件,以便我们可以精确定位它并了解它何时发生,或者“某件事何时发生?”,通常基于 日期时间。
从本质上讲,这两者都与时间有关,但测量方式不同。
对于 Erlang,简短的答案是,你应该使用 erlang:monotonic_time/0-1 来计算持续时间,使用 erlang:system_time/0-1 来获取系统时间(例如 UNIX 时间戳)。如果你想了解 原因,你需要阅读本章的其余部分。
日期时间通常基于日历日期(大多数读者可能使用 公历)以及给定的小时、分钟和秒值,以及时区,并且可选地包含毫秒或微秒的更高精度值。这个值需要人类能够理解,并且完全植根于人们在一段时间内达成共识的社会系统:我们都知道公元 1000 年指的是时间的某个特定部分,即使我们目前的公历是在 1582 年引入的,并且从技术上讲,之前的任何日期都没有在该系统下发生过——它们可能发生在儒略历或玛雅历下,而不是公历下。整个概念最终与天文现象相关联,例如地球的轨道或 平均太阳日。
另一方面,时间间隔,特别是对于计算机而言,是基于我们计数的一些循环事件。水钟 或沙漏具有水滴或沙粒下降的特定速率,当它为空时,一定的时间段就会过去。现代计算机使用各种机制,如 时钟信号、晶体振荡器,或者如果你非常高级,可以使用 原子钟。通过将这些循环可计数事件与平均太阳日等概念同步,我们可以将测量的周期调整到更广泛的参考点,并将我们的两个时间核算系统结合起来:持续时间和时间点的精确定位可以协调起来。
我们人类习惯于将这两个概念视为同一个“时间”值的两个方面,但是当涉及到计算机时,它们实际上并不擅长同时做这两件事。如果我们保持这两个概念的不同,将会非常有帮助:持续时间与时间点不同,应该以不同的方式处理。
举个例子,许多程序员了解Unix时间戳(自1970年1月1日以来的秒数),许多程序员也了解UTC作为一种标准。但是,很少有开发人员意识到两者实际上很难转换,因为UTC处理闰秒,而Unix时间戳则不处理,这可能会导致各种奇怪、有趣的问题。在软件中交替使用它们可能会引入细微的错误。
一个特别的挑战是计算机时钟在较长时间内并不特别准确,这个概念被称为时钟漂移。其结果之一是,虽然我们在短时间间隔内(几分钟或几小时)可能拥有非常好的分辨率,但在几周、几个月或几年内,时钟会漂移很多。计算机时钟的频率在此处或那里有所不同,但总体上变化不大。您将进行的所有短时间计算都将正常进行,但它们不足以跟踪大多数较长时间段。相反,需要诸如NTP之类的协议,以便通过网络将计算机时钟与更准确(且更昂贵)的时钟重新同步。
这意味着您的计算机上的时间可能会随机跳动是意料之中的。如果操作员只是玩弄时区或系统时间之类的东西,这种情况就更常见了。
在Erlang中处理时间
您的计算机处理时间的方式基于前面提到的时钟,这些时钟只是通过计数微秒或毫秒(取决于硬件和操作系统)来递增。为了以对我们人类有意义的单位表示时间,会从某个纪元(任意起点)到某个时间标准(UTC)进行转换。由于计算机时钟会随着时间推移而漂移和偏移,因此会保留一个偏移量值,以便校正本地不断增加的时钟,使其对人们有意义。这通常都是隐藏的,除非您知道在哪里查找,否则您不会知道它正在发生。
Erlang的运行时系统使用相同类型的机制,但将其明确化。它公开了两个时钟
- 一个单调时钟,这意味着一个仅作为计数器始终返回递增值(或如果在同一微秒内调用它,则返回与之前相同的数字)的时钟。它可以具有高精度,对于计算时间间隔很有用。
- 一个系统时钟,它公开了作为人类通常关心的时间。这通常是通过使用Unix POSIX时间(自1970年1月1日以来的秒数)来完成的,Unix POSIX时间被各地的计算机广泛使用,并且存在大量用于所有其他类型时间格式的转换库。它为人类时间提供了一种最低公分母。
总的来说,系统上的所有时钟最终可能看起来像图1
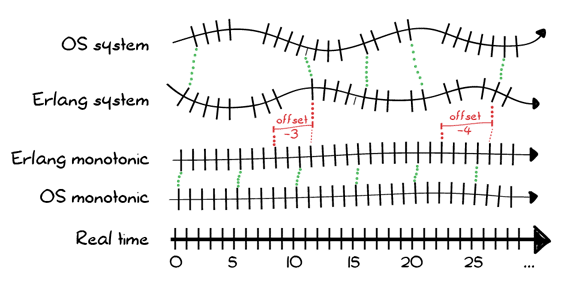
存在一些真实感知时间(如果我们忽略相对论效应,我们将假设它相当恒定),计算机时钟或多或少会与之匹配。电压、温度、湿度和硬件质量都可能影响其可靠性。Erlang VM提供自己的单调时钟,该时钟与硬件时钟(如果有)同步,并允许一些额外的控制,我们很快就会描述。
系统时间本身总是计算为其底层单调时钟的给定偏移量。目标是获取硬件时钟的任意时钟滴答数,并将其转换为自1970年以来的秒数,然后可以将其转换为其他格式。
如果偏移量为常数0,则VM的单调时间和系统时间将相同。如果偏移量正向或负向修改,则可以使Erlang系统时间与OS系统时间匹配,而Erlang单调时间保持独立。在实践中,单调时钟可能为某个较大的负数,并且系统时钟可以通过偏移量修改以表示正的POSIX时间戳。
这意味着在Erlang中,您需要针对特定用例使用以下函数
erlang:monotonic_time/0-1用于Erlang单调时间。它可能会返回非常低的负数,但它们永远不会变得更负。您可以使用类似T0=erlang:monotonic_time(millisecond), do_something(), T1=erlang:monotonic_time(millisecond)的内容并通过计算T1 - T0来获取操作的总持续时间。请注意,跨比较的时间单位应相同(请参阅通知)。erlang:system_time/0-1用于Erlang系统时间(应用偏移量后),当您需要Unix时间戳时erlang:time_offset/0-1用于找出Erlang单调时钟和Erlang系统时钟之间的差异calendar:local_time/0返回转换为操作系统的当前时钟(即用户当前时区和夏令时)的系统时间,格式为{{Year, Month, Day}, {Hour, Minute, Second}}calendar:universal_time/0返回转换为当前UTC时间的系统时间,格式为{{Year, Month, Day}, {Hour, Minute, Second}}。
提示
erlang模块中处理时间的函数几乎都带有一个Unit参数,该参数可以是second、millisecond、microsecond、nanosecond或native之一。默认情况下,返回的时间戳类型为本地格式。单位在运行时确定,并且可以使用erlang:convert_time_unit(Time, FromUnit, ToUnit)在时间单位之间进行转换。例如,erlang:convert_time_unit(1, seconds, native)返回1000000000。
calendar模块还包含更多实用程序函数,例如日期验证、转换为和从RFC3339日期时间字符串(2018-02-01T16:17:58+01:00)转换、时间差以及转换为天、周或检测闰年。
最后一种工具是一种新型监控器,可用于检测时间偏移量何时跳跃。它可以调用为erlang:monitor(time_offset, clock_service)。它返回一个引用,当时间漂移时,接收到的消息将为{'CHANGE', MonitorRef, time_offset, clock_service, NewTimeOffset}。
时间扭曲
如果在正确的上下文中使用前面的函数,您几乎永远不会遇到处理时间的问题。您现在唯一需要关心的是如何处理奇怪的情况,例如主机计算机进入睡眠状态并在唤醒时使用全新的时钟、处理系统管理员玩弄时间、NTP 强制时钟向前和向后跳跃等等。不关心它们会导致您的系统以非常奇怪的方式运行。
幸运的是,Erlang VM 允许您从预先建立的策略中进行选择,只要您始终在正确的时间使用正确的函数(单调时钟用于间隔和基准测试,系统时间用于精确定位事件),您就可以选择任何您认为更合适的选项。为正确的用例选择正确的函数可确保您的代码是时间扭曲安全的。
这些选项可以通过将+C(扭曲模式)和+c(时间校正)开关传递给erl可执行文件来传递。扭曲模式(+C)定义了如何处理单调时间和系统时间之间的偏移量,时间校正(+c)定义了当系统时钟更改时VM将如何调整其公开的单调时钟。
+C multi_time_warp +c true:时间偏移量可以在任何时间更改,没有任何限制以提供良好的系统时间,并且VM可以调整Erlang单调时钟频率以使其尽可能准确。这是您想要在任何现代平台上指定的选项,并且往往具有更好的性能、更好的扩展性和更好的行为。+C no_time_warp +c true:在VM启动时选择时间偏移量,然后不再修改。相反,单调时钟会加速或减速以缓慢校正时间漂移。这是出于向后兼容性原因的默认模式,但您可能希望选择更符合正确时间使用的其他模式。+C multi_time_warp +c false:时间偏移量可以在任何时间更改,但Erlang单调时钟频率可能不可靠。如果OS系统时间向前跳跃,则单调时钟也将向前跳跃。如果OS系统时间向后跳跃,则Erlang单调时钟可能会短暂暂停。+C no_time_warp +c false:在VM启动时选择时间偏移量,然后不再修改。允许单调时钟停滞或向前跳跃一大步。您通常不希望使用此模式。+C single_time_warp +c true:这是一种特殊的混合模式,用于在您知道Erlang在OS时钟同步之前启动的嵌入式硬件上(例如,您在NTP同步发生之前启动软件)。当VM启动时,Erlang单调时钟保持尽可能稳定,但不会进行系统时间调整。一旦在OS级别完成时间同步,用户调用erlang:system_flag(time_offset, finalize),Erlang系统时间会扭曲一次以匹配OS系统时间,然后时钟变得等效于no_time_warp下的时钟。+C single_time_warp +c false:这是一种特殊的混合模式,用于在您知道Erlang在OS时钟同步之前启动的嵌入式硬件上(例如,您在NTP同步发生之前启动软件)。不会尝试将Erlang系统时间与OS系统时间同步,并且OS系统时间的任何更改都可能影响Erlang单调时钟。一旦在OS级别完成时间同步,用户调用erlang:system_flag(time_offset, finalize),Erlang系统时间会扭曲一次以匹配OS系统时间,然后时钟变得等效于no_time_warp下的时钟
您通常希望始终将+c true作为选项(它是默认选项),并强制使用+C multi_time_warp(这不是默认选项)。如果您想模拟旧的Erlang系统(其中调整时钟频率),请选择+C no_time_warp,如果您在嵌入式系统中工作,其中第一次时钟同步可能会在时间上跳跃很远,并且之后您期望它更稳定并且您不希望使用+C multi_time_warp(您应该希望使用它!),那么请查找single_time_warp。
简而言之,如果可以,请选择+C multi_time_warp +c true。它是目前最准确的时间处理选项。
SSL配置
TLS背景信息
即将推出…
在Erlang中处理TLS
即将推出…