Kubernetes 是一个容器编排系统。当后端包含许多需要跨节点保持运行的不同服务,并且需要进行跨服务通信和扩展时,编排系统就变得至关重要。随着容器的普及,使用 Kubernetes 进行编排也越来越受欢迎。
借助容器和 Kubernetes,我们可以在系统中的所有语言和运行时环境中使用通用的部署、发现、扩展和监控方法。在本章中,我们将介绍 Kubernetes 的核心组件,以及如何使用它们来部署和管理我们在前几章中构建的 service_discovery 服务。
运行 Kubernetes
为了开发和测试 Kubernetes 部署,我们需要在本地运行 Kubernetes 进行测试。以下部分使用 microk8s 作为本地测试 Kubernetes,但应该适用于任何本地或云端运行 Kubernetes 的选项。在需要提供有关本地测试的具体说明时,将使用 microk8s。持续集成和部署到生产环境的说明将使用 Google Kubernetes Engine。但大部分内容应该可以轻松地与以下两节中的任何产品一起使用。
本地
- microk8s:来自 Ubuntu 背后公司 Canonical 的产品,但在许多 Linux 发行版、Windows 和 MacOS 上运行。microk8s 易于安装和使用,并且在本地运行,而不是像 minikube 那样在虚拟机中运行,因此占用资源较少。
- minikube:最古老、最灵活的选项,现在也是 Kubernetes 项目的正式组成部分。
minikube支持各种虚拟机管理程序,并且可以选择在不创建新虚拟机的情况下运行,但它仍然建议在 Linux 虚拟机中运行。 - k3s 和 k3d:k3s 是来自 Rancher Labs 的轻量级 Kubernetes。k3s 删除了遗留和非默认功能以缩减大小,并用 SQLite3 替换了 etcd,这使得 k3s 成为 CI 和本地测试的不错选择。k3d 是一个在 Docker 中运行 k3s 的辅助工具。
- kind:Kubernetes in Docker 是一个由 Kubernetes SIG 支持的项目,用于在 Docker 中运行 Kubernetes,最初是为了测试 Kubernetes 本身。
- Docker for Mac Kubernetes:在 MacOS 上运行时,最容易上手。
生产环境
所有大型云提供商都提供托管的 Kubernetes 集群
- Google Kubernetes Engine:本章在不使用 microk8s 时使用了 Google Cloud,因为它提供了 $300 的注册新用户赠送额度
- Digital Ocean Kubernetes
- AWS Elastic Container Service for Kubernetes
- Azure Kubernetes Service
还有 许多其他选项 可用于部署到云端或本地。在选择解决方案时,需要考虑许多因素,例如对于现有公司,其服务当前托管在哪里。幸运的是,使用 Kubernetes,您的部署不会锁定到任何一个提供商。
部署
在 Kubernetes 中,容器是 Pod 的一部分。每个 Pod 有一个或多个容器,以及 0 个或多个 init-containers,这些容器在启动其他容器之前先运行到完成。对于应用程序,使用称为 Deployment 的更高级别的抽象,因此无需手动创建单个 Pod 来进行部署或扩展。Deployment 是创建和更新应用程序 Pod 的一种声明式方式。
每个 Kubernetes 资源都在一个 yaml 文件中定义,该文件包含 apiVersion、资源的 kind、metadata(例如名称)以及资源的规范。
apiVersion: apps/v1
kind: Deployment
metadata:
name: service-discovery
spec:
[...]
我们将在本文中介绍的 Deployment 规范条目包括 selector、replicas 和 template。selector 是指定哪些 Pod 属于 Deployment 的规范。matchLabels 表示具有标签 app(值为 service-discovery)且在同一 Namespace 中的 Pod 将被视为 Deployment 的一部分。replicas 声明应运行多少个 Pod 实例。
spec:
selector:
matchLabels:
app: service-discovery
replicas: 1
template:
[...]
template 部分是一个 Pod 模板,它定义了 Deployment 要运行的 Pod 的规范。
template:
metadata:
labels:
app: service-discovery
spec:
shareProcessNamespace: true
containers:
- name: service-discovery
image: service_discovery
ports:
- containerPort: 8053
protocol: UDP
name: dns
- containerPort: 3000
protocol: TCP
name: http
- containerPort: 8081
protocol: TCP
name: grpc
首先,Pod 元数据设置标签以与 Deployment 规范中的 selector 匹配——在即将到来的部分 使用 Kustomize 简化部署 中,我们将看到如何消除两次定义 labels 的需要。然后,Pod 规范包含一个容器列表。在本例中,有一个容器公开了用于通过 DNS、HTTP 和 GRPC 访问的端口。
僵尸进程终结者!
在 Docker 章节 中讨论的僵尸进程(退出但其 PID 仍然存在,因为父进程没有调用 wait())问题也适用于使用 Kubernetes 运行的容器。一种防止僵尸进程的方法(也是 service_discovery 项目中使用的方法)是在 Pod 中的容器之间使用共享进程命名空间。
这可以通过在 Pod 规范中使用 shareProcessNamespace: true 来实现。此设置意味着在容器中启动的进程不会成为 PID 1。相反,PID 1 是 Kubernetes 的 pause 容器。pause 容器始终是 Pod 中的父容器,但使用此设置,使其成为 Pod 中所有进程的 PID 1,它能够回收任何容器中可能产生的僵尸进程。
容器资源
Pod 规范中的每个容器规范都可以包含内存和 CPU 的资源请求和限制。请求用于调度 Pod。调度涉及选择一个节点,该节点的请求 CPU 和内存可用(未被节点上的其他 Pod 请求)。
resources:
requests:
memory: "250Mi"
cpu: "500m"
limits:
memory: "1Gi"
cpu: "2000m"
此外,CPU 请求将转换为 cgroup 属性 cpu.shares。每个 CPU 被视为 1024 个切片,而 CPU 请求告诉内核尝试为进程提供多少个切片。但是,当仅设置切片时,进程最终可以使用的量没有上限。为了限制使用过多 CPU 时间的进程,我们需要 Kubernetes 资源限制。
限制将转换为 Linux 内核调度程序对进程执行的 CPU 带宽控制。带宽控制具有一定的周期(以微秒为单位),以及配额(进程在某个周期内可以使用的最大微秒数)。周期始终为 100000 微秒,因此在上面示例中,CPU 限制设置为 2000m,设置的 cgroup 配额将为 200_000,这意味着每 100_000 微秒可以使用 2 个 CPU。
如果在某个周期内超过了限制,内核将通过不允许进程再次运行直到下一个周期来限制进程。这就是为什么正确设置使用的 Erlang VM 调度程序数量以及限制 VM 执行的繁忙等待量非常重要的原因。
繁忙等待是 Erlang 调度程序进入的紧密循环,在等待更多工作要执行之前最终进入睡眠状态。此紧密循环会消耗 CPU 来等待执行实际工作,并且会导致性能大幅下降,因为您的 Erlang 程序可能会受到内核调度程序的限制。然后,当有实际工作要执行时,它可能发生在一个 Erlang VM 完全没有获得 CPU 切片的周期中。如果 VM 运行的调度程序数量超过分配给它的 CPU 数量,情况会更糟。我们认为 2000m 的 CPU 限制意味着 2 个 CPU 内核,但它实际上并没有将进程限制在 2 个内核上。如果正在使用 8 个调度程序,并且节点上有相同数量的内核,则这 8 个调度程序仍将分布在所有内核上并并行运行。但是配额仍然是 200000,并且当 8 个调度程序占用 8 个内核的时间时,更有可能超出配额。即使没有繁忙等待,调度程序也必须执行自己的工作,并且在尝试保持在某些 CPU 使用约束范围内时可能会造成不必要的开销。
为了禁用调度程序繁忙等待,我们设置 VM 参数 +sbwt 在 vm.args.src 中,如下所示
+sbwt ${SBWT}
从 OTP-23 开始
在 2020 年发布的 OTP-23 中,Erlang VM 能够“感知容器”,并且会根据容器分配的资源自动设置适当数量的活动调度程序。在 OTP-23 之前,需要 +S 参数将活动调度程序的数量设置为等于容器的 CPU 限制。
此外,从 OTP-23 开始,+sbwt 默认值为 very_short。这是一个改进,但您可能仍然希望在 Kubernetes 或类似环境中将该值设置为 none。但是,一如既往,请务必进行基准测试以找到适合您的特定工作负载的最佳值。
容器环境和 ConfigMap
正如我们在发布章节中所看到的,运行时配置是通过 vm.args.src 和 sys.config.src 中的环境变量替换来完成的。因此,我们必须将这些变量插入到容器的环境中。Kubernetes Pod 中的每个容器都可以有一个 env 字段,声明一组环境变量。最简单的情况是显式提供 name 和 value
env:
- name: LOGGER_LEVEL
value: error
- name: SBWT
value: none
此配置将导致环境变量 LOGGER_LEVEL 的值为 error。
必须根据正在运行的容器的状态设置其他环境变量。一个示例是根据 Pod 的 IP 设置 NODE_IP 变量
env:
- name: NODE_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
fieldRef 下的 status.podIP 声明将在创建 Pod 时返回当前 Pod 的 IP。
像 LOGGER_LEVEL 这样的用户定义的环境变量可以在 Kubernetes 资源中更好地跟踪,该资源专门用于配置,称为 ConfigMap。ConfigMap 包含键值对,并且可以从文件、文件目录或字面值填充。在这里,我们将使用字面值将 LOGGER_LEVEL 设置为 error
apiVersion: v1
kind: ConfigMap
metadata:
name: configmap
data:
LOGGER_LEVEL: error
然后回到 Deployment 资源中,LOGGER_LEVEL 值可以成为对 ConfigMap 的引用
env:
- name: LOGGER_LEVEL
valueFrom:
configMapKeyRef:
name: configmap
key: LOGGER_LEVEL
将 ConfigMap 中定义的所有变量作为容器的环境变量引入的快捷方式可以使用 envFrom 完成
envFrom:
- configMapRef:
name: configmap
现在,ConfigMap 中定义的所有变量都将添加到容器中,而无需单独指定每个变量。有关定义 ConfigMap 的更多信息,请参阅即将到来的部分 使用 Kustomize 简化部署。
提示
更新 ConfigMap 中的值不会触发引用该 ConfigMap 的 Deployment 重新启动其容器并使用新的环境变量。相反,当配置更改时更新容器的方法是创建一个具有必要更改的新 ConfigMap 以及一个新名称,然后修改 Deployment 下 configMapRef 中引用的 ConfigMap 的名称。旧的 ConfigMap 最终将被 Kubernetes 垃圾回收,因为它们在任何地方都没有被引用,并且 Deployment 将使用新配置重新创建其 Pod。
Init Containers
我们发布的 service_discovery 依赖于 Postgres 数据库来存储状态,为了确保数据库在运行我们的容器之前正确设置,我们将使用一个 Init Container。每个 Init Container 都是一个在 Pod 中任何主容器运行之前完成运行的容器。我们用于运行迁移的数据库迁移工具 flyway 用于在允许主容器运行之前验证数据库是否是最新的
volumes:
- name: migrations
emptyDir:
medium: Memory
initContainers:
- name: flyway
image: flyway/flyway:9.22
name: flyway-validate
args:
- "-url=jdbc:postgresql://$(POSTGRES_SERVICE):5432/$(POSTGRES_DB)"
- "-user=$(POSTGRES_USER)"
- "-password=$(POSTGRES_PASSWORD)"
- "-connectRetries=60"
- "-skipCheckForUpdate"
- validate
volumeMounts:
- name: migrations
mountPath: /flyway/sql
env:
- name: POSTGRES_SERVICE
value: POSTGRES_SERVICE
- name: POSTGRES_DB
value: POSTGRES_DB
- name: POSTGRES_USER
value: POSTGRES_USER
- name: POSTGRES_PASSWORD
value: POSTGRES_PASSWORD
- name: service-discovery-sql
image: service_discovery
command: ["/bin/sh"]
args: ["-c", "cp /opt/service_discovery/sql/* /flyway/sql"]
volumeMounts:
- name: migrations
mountPath: /flyway/sql
卷 migrations 仅存在于内存中,用于将当前的 SQL 迁移文件从发布镜像复制到 flyway 容器将用于运行验证的共享目录。使用带有 medium memory 的 emptyDir 类型卷,因为我们不使用此卷来持久化任何数据,仅用于在两个 Init Container 之间共享。如果未包含 medium: Memory,则 emptyDir 会在主机文件系统上创建,但对于每个新的 Pod,它最初仍然为空,并且在 Pod 被删除时会删除。
就绪性、存活性以及启动探针
Pod 中的每个容器都可以定义一个 readiness(就绪性)、一个 liveness(存活性)和一个 startup(启动)探针。探针定义为在容器中执行的命令,对给定端口和路径发出的 HTTP GET 请求,或尝试打开到特定端口的 TCP 连接。
虽然 Kubernetes 会重启任何失败的容器,但在某些情况下,进程可能会变得无响应,例如死锁。livenessProbe 可用于此类情况,其中停止响应会提示重启。因此,如果包含了 livenessProbe,则应将其保持极其简单。通常,完全省略 livenessProbe 并依赖于节点崩溃、基于指标的警报和自动扩展更安全。
自动扩展的一部分基于 readinessProbe。readinessProbe 告诉 Kubernetes Pod 已准备好接收流量。当 Pod 由于容器失败 readinessProbe 而变得 unready 时,它将从 Service 中移除,导致流量被定向到剩余的 Pod,从而增加它们的负载,然后将启动一个新的 Pod。
不为此目的使用 livenessProbe 意味着容器仍然可用,因为它们没有被杀死,并且可以检查检查失败的原因。这可能意味着附加一个 shell(如果它没有完全冻结)或强制写入崩溃转储。在资源非常受限的环境中,您可能更喜欢使用 livenessProbe,以便立即清理死锁容器及其 Pod,而不是等待手动干预和自动扩展器在负载下降后缩减规模。
readinessProbe 的另一个用途是,如果应用程序必须定期执行一些不需要处理请求的工作,或者必须进行某种维护,它可以返回 503 状态响应以表示就绪性,从而导致它从 Service 后端中移除。
在 Pod 配置中,无需任何特殊操作即可实现优雅关闭,无论是在部署期间、livenessProbe 失败还是缩减规模期间。当 Kubernetes 发送 SIGTERM 信号以指示关闭时,Erlang 将调用 init:stop()。如 发布 中所述,每个应用程序都将按其启动的反序停止,并且每个应用程序的监督树将按反序终止子项。
默认情况下,进程最多可以等待 30 秒(可以使用 terminationGracePeriodSeconds PodSpec 选项进行配置),然后 Kubernetes 会发送 SIGKILL 信号,强制进程终止。
关于部署和 readinessProbe 的一个重要说明是,如果 readinessProbe 从未通过的行为。在部署期间,如果 Pod 从未通过其 readinessProbe,那么根据部署策略,来自部署先前版本的 Pod(处于 Ready 状态)可能会保留,直到它们通过为止。这将在后续部分 滚动部署 中详细介绍。
在 service_discovery 项目中,仅定义了 readinessProbe,目的是在不终止容器的情况下将 Pod 从 Service 后端移除
readinessProbe:
httpGet:
path: /ready
port: http
initialDelaySeconds: 0
periodSeconds: 10
通过此配置,我们预计初始检查至少会失败一次,因为 service_discovery_http 应用程序绑定到端口以侦听 HTTP 请求之前的实际启动时间超过 0 秒。这将导致 Probe 处理的 连接被拒绝 错误
service-disc… │ [event: pod service-discovery-dev/service-discovery-dev-645659d699-plxfw] Readiness probe failed: Get "http://10.244.0.114:3000/ready": dial tcp 10.244.0.114:3000: connect: connection refused
尽管失败且 periodSeconds 为 10,但 Pod 准备好可能不会花费 10 秒。使用 initialDelaySeconds 为 0,readinessProbe 会在启动时立即进行检查,并且不会等待配置的 periodSeconds 来再次检查。因为服务在启动时几乎不做任何事情,所以它将通过第二次检查。如果它没有通过,它将等待 periodSeconds 直到再次检查它并且 Pod 变为就绪。
为了尽可能简单,readinessProbe 在 service_discovery_http 中定义为
handle('GET', [<<"ready">>], _Req) ->
{ok, [], <<>>};
这意味着它匹配对 /ready 的 GET 请求,并立即返回 200 响应。除了能够接收和响应 HTTP 请求之外,没有其他服务功能检查。
滚动部署
Kubernetes Deployment 资源具有可配置的 策略,用于在部署新版本的镜像时发生的情况。service_discovery Deployment 使用滚动更新策略。另一种策略是 Recreate,这意味着 Kubernetes 首先终止 Deployment 中的所有 Pod,然后启动新的 Pod。对于 RollingUpdate 策略,Kubernetes Deployment 控制器将启动新的 Pod,然后终止旧的。有两个配置变量来告诉控制器允许比所需数量多多少个 Pod(maxSurge)以及在部署期间允许多少个不可用(maxUnavailable)。
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0
maxSurge: 25%
service_discovery 配置了 maxUnavailable 为 0 和 maxSurge 为 25%。这意味着如果它已扩展到四个副本,则在部署期间将启动一个新的 Pod,当该 Pod 的 readinessProbe 通过时,一个旧的 Pod 将开始终止,并且将启动一个新的 Pod。此过程将继续四次。
服务
Service 是一种资源,用于定义如何在网络上公开应用程序。每个 Pod 都有自己的 IP 地址,并且可以公开端口。Service 提供单个 IP 地址(Service 的 ClusterIP),并且可以将该 IP 上的端口映射到应用程序的每个 Pod 的公开端口。在以下资源定义中,创建了一个名为 service-discovery 的 Service,其选择器为 app: service-discovery,以匹配上一节中创建的 Pod
kind: Service
apiVersion: v1
metadata:
name: service-discovery
spec:
selector:
app: service-discovery
ports:
- name: dns
protocol: UDP
port: 8053
targetPort: dns
- name: http
protocol: TCP
port: 3000
targetPort: http
- name: grpc
protocol: TCP
port: 8081
targetPort: grpc
Deployment 的容器公开了三个端口,并为每个端口命名,即 dns、http 和 grpc。Service 使用这些名称作为其公开的每个端口的 targetPort。将此资源应用于 Kubernetes 集群后,将有一个 IP 在这三个端口上侦听,并将代理到正在运行的 Pod 之一。
使用代理(kube-proxy)将流量路由到 Pod,而不是将每个 Pod IP 添加到 DNS 记录中,因为 Service 实际运行的 Pod 的变化率很高。如果使用 DNS,则需要较短或零生存时间 (TTL),并依赖客户端完全尊重 TTL 值。让每个请求都通过代理路由意味着,只要代理的数据已更新,就会将正确的 Pod 集路由到。
Kubernetes 感知的 DNS 服务(如 CoreDNS)将监视新的 Service 并为每个服务创建 DNS 记录 [service-name].[namespace]。当使用命名端口时,例如 service-discovery Service 中的三个端口,还会创建以下形式的 SRV 记录:_[name]._[protocol].[service-name].[namespace]。查询 DNS 服务以获取 SRV 记录,例如 _http._tcp.service-discovery.default 将返回 Service DNS 名称 service-discovery.default 和端口 3000。
在后面关于集群的部分中,我们将看到如何使用 Headless Service(ClusterIP 设置为 None 的 Service)资源和命名端口通过分布式 Erlang 连接 Erlang 节点,而无需 Erlang 端口映射守护程序 (epmd)。
使用 Kustomize 简化部署
现在我们已经讨论了用于应用程序的两个主要 Kubernetes 资源,我们可以深入了解如何实际编写和部署这些资源。前面各节中显示的每个资源的 YAML 未用于部署的原因是它处于静态状态,有时会重复(例如,必须在 Deployment 中两次定义相同的标签集),并且需要手动修改或复制资源以部署到需要不同配置的不同环境中。我们需要一些东西,使更改变得容易且清晰,例如更新容器中使用的镜像、根据环境使用资源的不同名称或命名空间,或者根据环境使用 ConfigMap 的不同值。
有一些开源选项可用于处理 Kubernetes 资源。最流行的两个是 Helm 和 Kustomize。两者都是 Kubernetes 项目的一部分,但对问题的解决方案却大不相同。Helm 使用 Go 模板 来编写和渲染 YAML。有些人(包括作者)认为 YAML 模板过于复杂、容易出错,而且很烦人。幸运的是,另一个解决方案 Kustomize 不依赖于模板。
Helm 3
即使 Helm 未用于您项目本身的部署,它仍然可以用于部署依赖项。有许多 Helm Charts 可用,并且如果您只是为了内部使用,这可能是您希望向外界提供项目的方式。
除了模板之外,Helm 还存在许多问题,我们在这里不赘述,只是说它们在最新的主要版本 Helm v3 中得到了解决,该版本于 2019 年 11 月发布了第一个稳定版本。因此,我仍然建议您自己查看 Helm 的最新版本。
Kustomize 是一个 kubectl 内置工具(从 v1.14.0 开始),它提供了一种无需模板的方式来自定义 Kubernetes YAML 资源。我们将使用它为各种环境创建不同的配置,从开发环境 dev 开始,然后在下一节 Tilt 用于本地开发 中使用它来在本地运行 service_discovery。
设置是一个基础配置,具有用于不同环境的覆盖层。覆盖层可以添加其他资源并对基础层中的资源进行修改。基础配置和两个覆盖层的目录布局为
$ tree deployment
deployment
├── base
│ ├── default.env
│ ├── deployment.yaml
│ ├── init_validation.yaml
│ ├── kustomization.yaml
│ ├── namespace.yaml
│ └── service.yaml
├── overlays
│ ├── dev
│ │ ├── dev.env
│ │ └── kustomization.yaml
│ └── stage
│ ├── kustomization.yaml
│ └── stage.env
└── postgres
├── flyway-job.yaml
├── kustomization.yaml
├── pgdata-persistentvolumeclaim.yaml
├── postgres-deployment.yaml
└── postgres-service.yaml
基础 kustomization.yaml 包括 service_discovery 项目的主要资源,一个 Namespace、Deployment 和 Service
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: service-discovery
commonLabels:
app: service-discovery
resources:
- namespace.yaml
- deployment.yaml
- service.yaml
commonLabels 下的标签将添加到每个资源中,并通过能够删除 labels 条目和 selector 来简化前面部分中的 Deployment 配置。因此,现在 Deployment 资源(在 service_discovery 的 deployment/base/deployment.yaml 中找到)如下所示
apiVersion: apps/v1
kind: Deployment
metadata:
name: service-discovery
spec:
replicas: 1
template:
spec:
containers:
- name: service-discovery
image: service_discovery
[...]
Kustomize 在渲染资源时会在metadata下插入标签,并自动在spec的selector字段的matchLabels下插入相同的标签。要查看 Kustomize 生成的内容,请在基础上运行kubectl kustomize,它会将资源打印到标准输出。
$ kubectl kustomize deployment/base
[...]
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: service-discovery
name: service-discovery
namespace: service-discovery
spec:
replicas: 1
selector:
matchLabels:
app: service-discovery
template:
metadata:
labels:
app: service-discovery
[...]
改进Deployment创建的另一个功能是生成ConfigMap。在前面关于环境变量和 ConfigMap 的章节中,我们以一个包含来自ConfigMap数据中的环境变量的Deployment结束。
envFrom:
- configMapRef:
name: configmap
使用 Kustomize 的configMapGenerator,我们可以声明ConfigMap从任何包含类似VarName=VarValue行的文件中生成。
configMapGenerator:
- name: configmap
envs:
- dev.env
dev.env的内容是
LOGGER_LEVEL=debug
对于kubectl kustomize deployment/overlays/dev的输出中看到的生成的 ConfigMap 是
apiVersion: v1
data:
LOGGER_LEVEL: debug
kind: ConfigMap
metadata:
labels:
overlay: dev
name: configmap-dev-2hfc445577
namespace: service-discovery-dev
请注意,名称不再仅仅是configmap,而是configmap-dev-2hfc445577。如果内容发生变化,Kustomize 将创建一个具有不同名称的新ConfigMap,并且会更新对ConfigMap的任何引用。更新Deployment规范中对ConfigMap的引用可确保在配置更改时重新启动Pod。否则,仅仅修改ConfigMap不会导致正在运行的Pod更新。因此,在 Kustomize 输出中,Deployment将具有
- envFrom:
- configMapRef:
name: configmap-dev-2hfc445577
Secret也采用了相同的方式。
要一步应用 Kustomize 生成的资源,可以将-k选项传递给kubectl apply。
$ kubectl apply -k deployment/overlays/dev
此命令将根据dev覆盖生成资源并将其应用于 Kubernetes 集群。
数据库迁移
作业
Kubernetes Job 创建一个或多个Pod并运行它们,直到指定数量的Pod成功完成。对于service_discovery的数据库迁移,Job是一个Pod,其中包含一个运行Flyway的容器,并与一个initContainer共享一个Volume,该initContainer将SQL文件从正在部署的service_discovery镜像复制过来。作为initContainers意味着它们都必须运行到完成并成功(以状态码 0 结束),然后才能启动Pod的主容器。因此,在Job的Pod的主容器运行flyway migrate之前,包含迁移的容器(实际上是与我们用于运行Deployment的完整service_discovery版本相同的镜像)必须已成功将迁移复制到共享Volume的/flyway/sql目录下。
apiVersion: batch/v1
kind: Job
metadata:
labels:
service: flyway
name: flyway
spec:
ttlSecondsAfterFinished: 0
template:
metadata:
labels:
service: flyway
spec:
restartPolicy: OnFailure
volumes:
- name: migrations
emptyDir:
medium: Memory
containers:
- args:
- "-url=jdbc:postgresql://$(POSTGRES_SERVICE):5432/$(POSTGRES_DB)"
- -user=$(POSTGRES_USER)
- -password=$(POSTGRES_PASSWORD)
- -connectRetries=60
- -skipCheckForUpdate
- migrate
image: flyway/flyway:9.22
name: flyway
volumeMounts:
- name: migrations
mountPath: /flyway/sql
env:
- name: POSTGRES_SERVICE
value: POSTGRES_SERVICE
- name: POSTGRES_DB
value: POSTGRES_DB
- name: POSTGRES_USER
value: POSTGRES_USER
- name: POSTGRES_PASSWORD
value: POSTGRES_PASSWORD
initContainers:
- name: service-discovery-sql
image: service_discovery
command: ["/bin/sh"]
args: ["-c", "cp /opt/service_discovery/sql/* /flyway/sql"]
volumeMounts:
- name: migrations
mountPath: /flyway/sql
使用Job进行迁移的问题在于,应用一组 Kubernetes YAML 资源无法更新已完成Job的镜像并使其重新运行。应用具有不同service_discovery镜像的相同名称的Job将导致错误。有几个选项可以解决此限制。
一个选项(截至 Kubernetes 1.16 仍处于 alpha 阶段)是在Job规范中设置ttlSecondsAfterFinished: 0。使用此设置,Job将在完成后的立即变得可以删除。然后,当下次部署应用新的 Kubernetes 资源时,将创建一个新的Job,而不是尝试更新上次部署的Job。
ttlSecondsAfterFinished选项仍处于 alpha 阶段,需要手动启用。您可以在 Google Cloud 上尝试此功能,方法是创建一个alpha 集群,但这些集群只能存在 30 天。另一种解决方案是手动(或使用可以在 CI 管道中运行的脚本)运行迁移并在部署完成后删除Job。
单独运行Job与主kubectl apply相比,一个优势在于,如果Job失败,则可以停止部署。
验证迁移
如果我们希望确保我们的service_discovery容器在数据库成功迁移之前不会启动,则可以使用flyway命令validate。运行flyway validate的容器将在其正在检查的数据库运行所有迁移后成功。生成的容器设置与上一节我们进行迁移时基本相同,但命令不是migrate而是validate,并且在这种情况下,flyway容器和将迁移复制到共享卷的容器都是initContainers。
apiVersion: apps/v1
kind: Deployment
metadata:
name: service-discovery
spec:
replicas: 1
template:
spec:
volumes:
- name: migrations
emptyDir: {}
initContainers:
- name: service-discovery-sql
image: service_discovery
volumeMounts:
- name: migrations
mountPath: /flyway/sql
command: ["/bin/sh"]
args: ["-c", "cp /opt/service_discovery/sql/* /flyway/sql"]
- image: flyway/flyway:9.22
name: flyway-validate
args:
- "-url=jdbc:postgresql://$(POSTGRES_SERVICE):5432/$(POSTGRES_DB)"
- "-user=$(POSTGRES_USER)"
- "-password=$(POSTGRES_PASSWORD)"
- "-connectRetries=60"
- "-skipCheckForUpdate"
- validate
volumeMounts:
- name: migrations
mountPath: /flyway/sql
env:
- name: POSTGRES_SERVICE
value: POSTGRES_SERVICE
- name: POSTGRES_DB
value: POSTGRES_DB
- name: POSTGRES_USER
value: POSTGRES_USER
- name: POSTGRES_PASSWORD
value: POSTGRES_PASSWORD
每个 init 容器都按顺序运行到完成,然后才能启动下一个容器,这使得在这种情况下顺序非常重要。如果将迁移文件复制到/flyway/sql的容器不在initContainers列表的第一个位置,并且 Kubernetes 需要在启动下一个容器之前运行到成功完成,则在运行flyway之前不会将迁移复制到卷中。
Tilt 用于本地开发
Tilt 是一种用于部署和更新 Docker 镜像以及 Kubernetes 部署的工具,用于本地开发目的。默认情况下,它只会针对本地 Kubernetes(例如microk8s、minikube等)构建和部署服务,以防止意外地将您的开发环境发送到生产环境!
开始使用 Tilt 的最简单方法是在本地 Kubernetes 集群中使用注册表。对于microk8s,可以轻松启用注册表,我们也需要 DNS,因此现在也启用它。
$ microk8s.enable registry
$ microk8s.enable dns
要允许主机 Docker 发布到此注册表,必须将其添加到/etc/docker/daemon.json中。
{
[...]
"insecure-registries" : ["localhost:32000"]
[...]
}
Tilt 根据项目根目录下的名为Tiltfile的文件工作。浏览service_discovery根目录下的Tiltfile,它以以下内容开头:
default_registry('127.0.0.1:32000')
default_registry设置将 Tilt 构建的 Docker 镜像推送到哪里,在这种情况下,使用在microk8s中启用的注册表。此行实际上不是必需的,因为 Tilt 会检测到正在使用启用了注册表的microk8s,并自动配置自己以使用该注册表。
接下来配置几个 Docker 镜像的构建,从service_discovery_sql开始。
custom_build(
'service_discovery_sql',
'docker buildx build -o type=docker --target dev_sql --tag $EXPECTED_REF .',
['apps/service_discovery_postgres/priv/migrations'],
entrypoint="cp /app/sql/* /flyway/sql"
)
此镜像根据Dockerfile目标dev_sql构建。
FROM busybox as dev_sql
COPY apps/service_discovery_postgres/priv/migrations/ /app/sql/
它仅包含 SQL 迁移文件并使用busybox,以便entrypoint可以使用cp。custom_build的第三个参数['apps/service_discovery_postgres/priv/migrations']告诉 Tilt 如果该目录(在本例中为 SQL 迁移文件)中的任何文件发生更改,则重新构建镜像。我们将在稍后了解当我们进入Tiltfile中的 kustomize 部署时如何使用此镜像。
请注意,使用了函数custom_build。如果适合您的需求,Tilt 提供了一个更简单的函数docker_build来构建 Docker 镜像。在service_discovery的情况下,我们在Dockerfile中使用了特定的targets,并希望确保使用buildx。
接下来构建的镜像是service_discovery,这是Deployment使用的主镜像。
custom_build(
'service_discovery',
'docker buildx build -o type=docker --target dev_release --tag $EXPECTED_REF .',
['.'],
live_update=[
sync('rebar.config', '/app/src/rebar.config'),
sync('apps', '/app/src/apps'),
run('rebar3 as tilt compile'),
run('/app/_build/tilt/rel/service_discovery/bin/service_discovery restart')
],
ignore=["rebar.lock", "apps/service_discovery_postgres/priv/migrations/"]
)
请注意,rebar.lock被显式忽略,这是因为它有时会在实际上没有更改时被重写,而 Tilt 不会进行比较以验证是否确实发生了更改,因此会在本地运行 Rebar3 时不必要地运行live_update指令。迁移文件也被忽略,因为这由另一个 Docker 镜像处理。
目标是dev_release,因为我们希望能够通过简单地重新编译并在正在运行的镜像中重新启动来执行实时更新。
# image to use in tilt when running the release
FROM builder as dev_release
COPY . .
RUN rebar3 as tilt release
ENTRYPOINT ["/app/_build/tilt/rel/service_discovery/bin/service_discovery"]
CMD ["foreground"]
每当文件更改时,live_update指令将在容器中运行。Rebar3 配置文件tilt对发布构建使用dev_mode,这意味着更新已编译的模块只需要运行compile,而无需重新构建整个发布版——有关dev_mode和发布构建的更多详细信息,请参阅Releases 章节——因此更新命令只需将apps目录同步到正在运行的容器,运行compile并重新启动发布版。
最后,在TiltFile中配置要部署的 Kubernetes 资源,并设置一个观察器,以便在任何 kustomize 文件更改时重新运行它。
k8s_yaml(kustomize('deployment/overlays/dev'))
watch_file('deployment/')
Tilt 内置支持 kustomize,因此我们使用kustomize('deployment/overlays/dev')来渲染dev覆盖并传递给k8s_yaml,后者告诉 Tilt 要部署和跟踪哪些 Kubernetes 资源。
dev覆盖的kustomization.yaml中与base覆盖的重要区别在于包含了 Postgres kustomize 资源和一个合并到base资源上的补丁。
bases:
- ../../base
- ../../postgres
patchesStrategicMerge:
- flyway_job_patch.yaml
fly_job_patch.yaml用于配置 Flyway 作业以与 Tilt 设置配合使用。
# For tilt we make an image named service_discovery_sql with the migrations.
# This patch replaces the image used in the flyway migration job to match.
apiVersion: batch/v1
kind: Job
metadata:
labels:
service: flyway
name: flyway
spec:
template:
spec:
initContainers:
- name: service-discovery-sql
image: service_discovery_sql
volumeMounts:
- name: migrations
mountPath: /flyway/sql
command: ["/bin/sh"]
args: ["-c", "cp /app/sql/* /flyway/sql"]
此补丁将Job资源中的镜像名称更改为service_discovery_sql,与Tiltfile中第一个custom_build镜像的名称相同。Tilt 将使用最新的标签更新镜像(它将其设置为 Docker 构建命令环境中的$EXPECTED_REF,在custom_build中),并重新运行Job。这样,当service_discovery在本地 Kubernetes 中运行时,如果添加了新的迁移,它将自动被提取并在数据库上运行,使我们的开发集群与我们的本地开发保持同步。
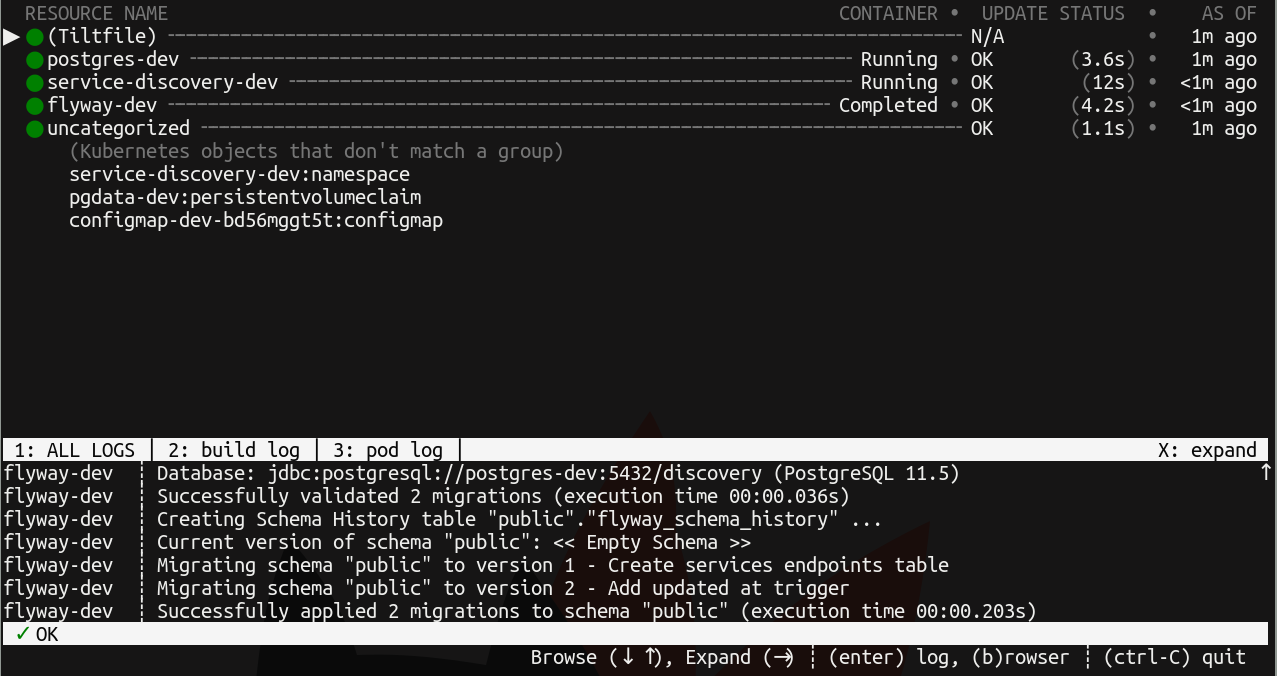
运行tilt后
$ tilt up
将弹出一个控制台 UI,显示启动传递给Tiltfile中的k8s_yaml的不同资源以及与其关联的日志的状态。
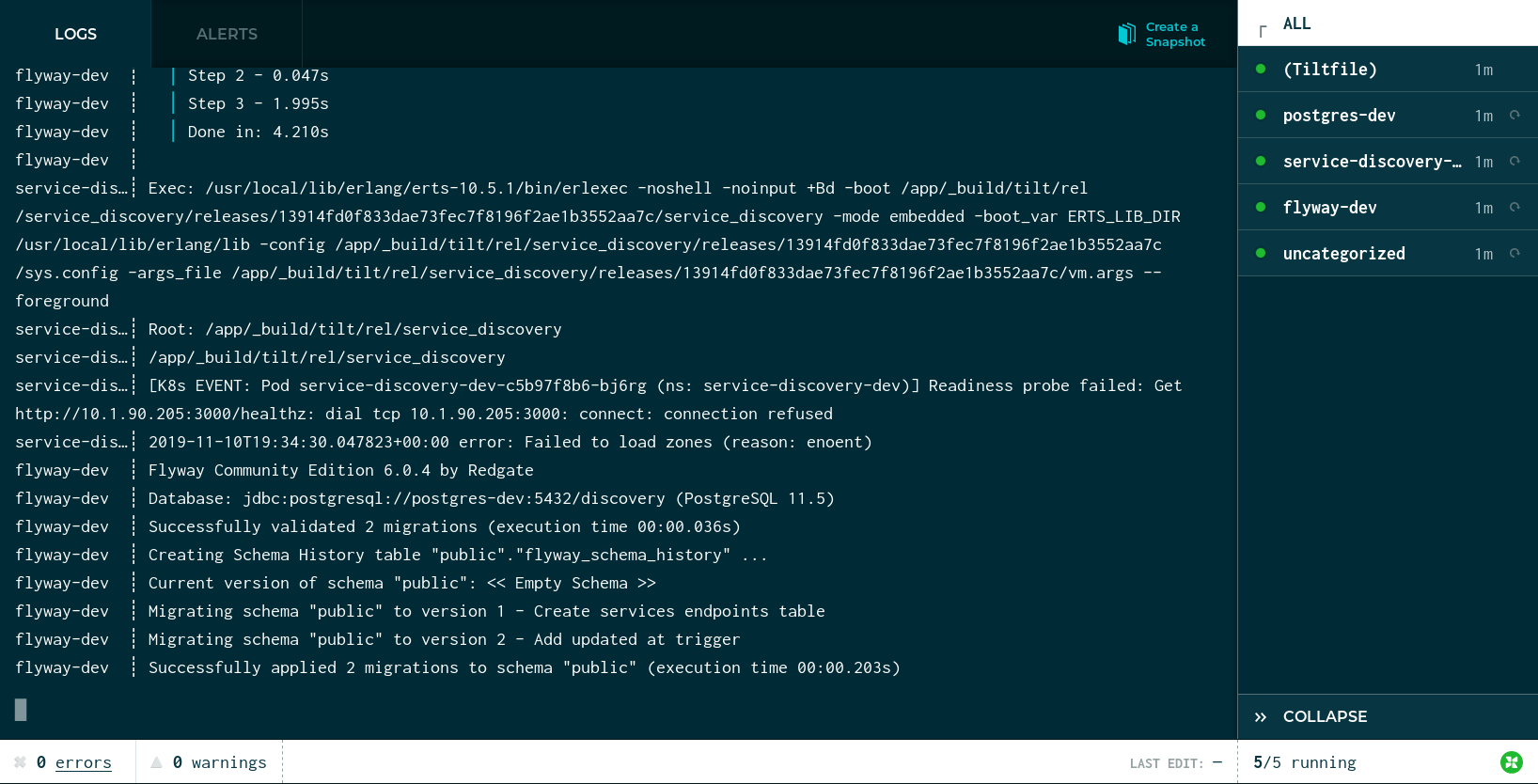
Tilt 还将自动在浏览器中打开一个页面,显示相同的信息。
使用kubectl可以找到service_discovery的 IP。
$ kubectl get services --namespace=service-discovery-dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
postgres-dev ClusterIP 10.152.183.116 <none> 5432/TCP 16m
service-discovery-dev ClusterIP 10.152.183.54 <none> 8053/UDP,3000/TCP,8081/TCP 16m
我们可以通过curl和dig与正在运行的 service_discovery 进行交互,以验证它是否正常运行。
$ curl -v -XPUT http://10.152.183.54:3000/service \
-d '{"name": "service1", "attributes": {"attr-1": "value-1"}}'
$ curl -v -XGET http://10.152.183.54:3000/services
[{"attributes":{"attr-1":"value-1"},"name":"service1"}]
集群
敬请期待…
StatefulSets
敬请期待…